 原理初探
原理初探
如果要深入的理解Git的原理, 我们可以从init开始, 逐步的分析每一步Git背后到底做了什么
经过前面的学习和操作, 我们知道git init会创建一个本地仓库
- 到底什么是本地仓库?
- 本地仓库到底又是如何管理代码的呢?
什么是本地仓库
通俗地讲, 就是本地存放代码(文件)的地方.
为了真正理解本地仓库到底放的什么, 需要搞清楚这样两个问题
- 本地仓库的结构
- 本地仓库是如何存储文件的
# 1 本地仓库的结构
当执行git init时, 会在当前目录下生成一个.git的目录, 这个目录就是本地仓库, 结构如下
演示
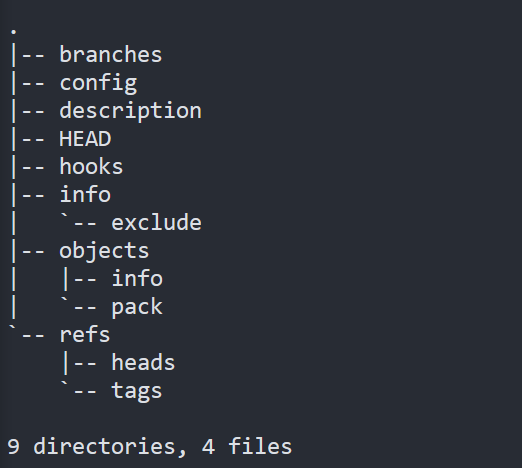
这里有很多的文件, 每一个文件都有具体的作用. 后面我们会一个个详细分析
我们先重点研究objects
git objects[对象]分为3类
- blob: 数据对象
- tree: 树对象
- commit: 提交对象
# 2 Git是如何保存代码的
Git在add时, 将文件的内容通过Hash SHA-1算法生成一个基于Hash值的键值对数据库
具体参考: Pro git (opens new window)

这里有几个概念我们展开讲
- 文件内容
- Hash算法
- 文件压缩
# 1) 文件内容
只要文件内容相同, 最终生成的Hash串就是一样的. 跟文件名无关
演示
注意
那么, Git为什么要这样设计, 以及文件名是在哪里处理的呢?
我知道大家有一堆的疑问, 我们先放一放.
在这里我只需要记住
提示
Git只会根据文件内容生成blob对象的Hash串, 和文件名无关
# 2) Git中的Hash算法
为了理解Git中的Hash算法, 我们先简单的介绍一下Hash算法
Hash算法
把任意长度的输入通过算法变换成固定长度的输出
- MD5: 128bit(16字节, 32个16进制)
- SHA1: 160bit(20字节, 40个16进制)
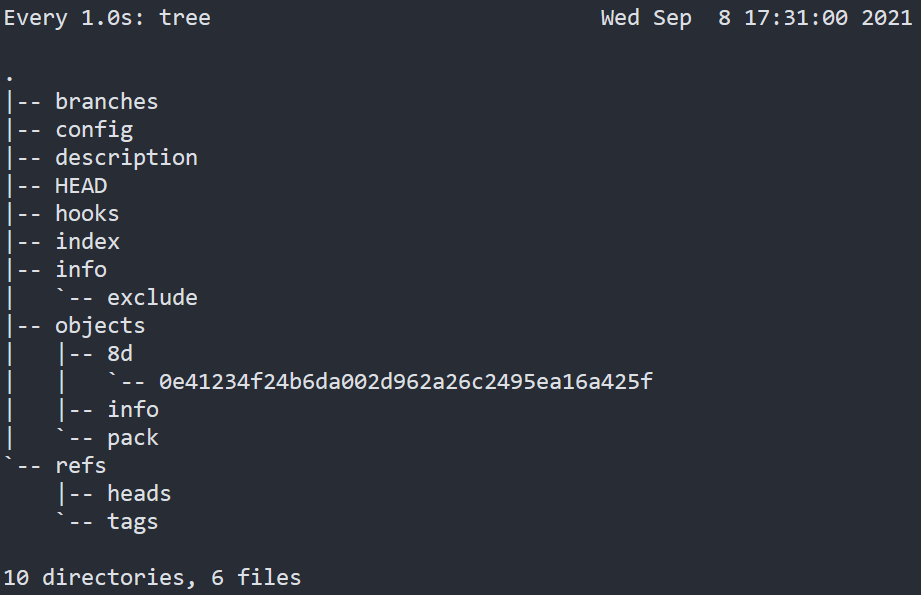
通过观察, 我们可以看到, 在objects目录下生成了一个文件:
- 文件名
8d0e41就是生成的Hash串 - 文件的内容是一串乱码, 这个是将文件经过zlib压缩后的数据
这样就就建立了一个映射关系, 即: 通过hash串, 找到对应的文件, 进而读取到文件的内容.
这种结构就是所谓的键值对数据库
- 键: Hash值
- 值: 文件内容
小结
Git的核心是一个键值对数据库, 里面有一种叫blob的数据对象负责存储压缩后的代码
具体算法
其实, Git生成Hash串的算法并不是很复杂. 通过下面算法就可以得到
'blob 长度\0内容'
下面借助Linux的命令得到同样的Hash串
echo 'blob 10\0hello git' | sha1sum
- 10: 是文件的长度, 除了
hello git9个字符外, 还有一个\n, 长度为10 hello git是文件的内容- sha1sum: 是Linux自带的计算Hash串的命令

注意
如果在windows下, 可能会得到不同的结果.
因为在windows下, 文件的末尾添加的是CRLF也就是\r\n, 而Linux下只有\n
因此, 可能会得出不一样的结果
# 3) 相关命令
Git提供一些命令来管理数据库, 这类命令(工具)不同于之前我们使用的命令, 如git add. git commit
为了区分, 我们将Git命令分为两类
- 底层(plumbing)命令
- 高层(porcelain)命令
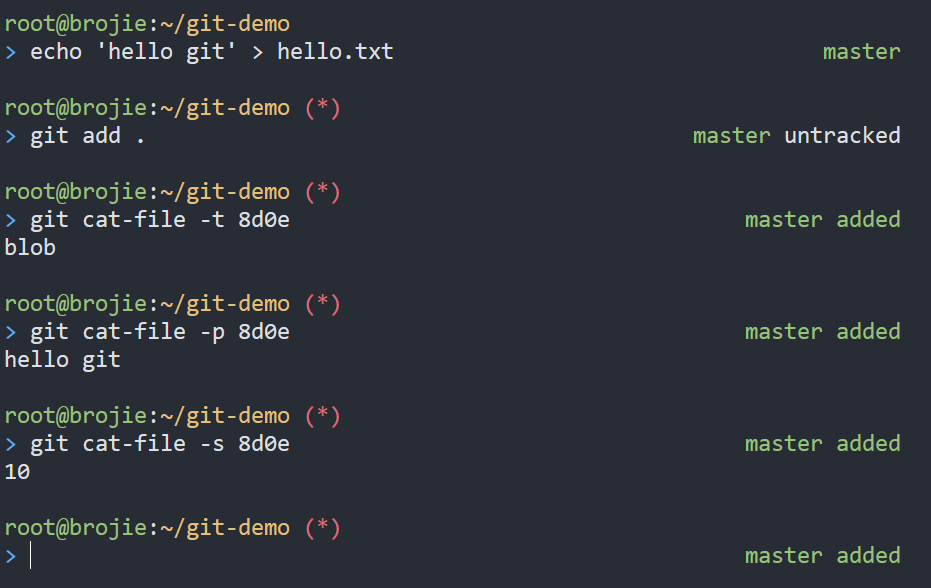
这里, 我们先介绍一个底层命令: git cat-file
通过git cat-file命令来查看object信息
# 获得object的类型
git cat-file -t hash
# 获得object的数据
git cat-file -p hash
# 获得object的长度
git cat-file -s hash
2
3
4
5
6
# 4) 小结
本节, 我们通过git add的过程, 知道了
- Git的object对象
- Git的键值对数据库
- Git的Hash算法
- cat-file命令
如果觉得有帮助, 可以微信扫码, 请杰哥喝杯咖啡~
